
Lec 10-1: Convolution
Deep_Learning study Lec10-1
Boostcourse의 ‘파이토치로 시작하는 딥러닝 기초’를 통한 공부와 정리 Post
Goal of Study
- 합성곱 (Convolution) 연산에 대해 알아본다.
Keyword
- 합성곱 (Convolution) 연산
- 필터(Filter)
- 스트라이드(Stride)
- 패딩(Padding)
- 풀링(Pooling)
1. 강의 요약
Convolution
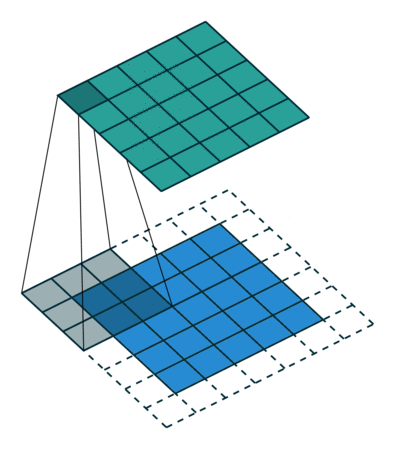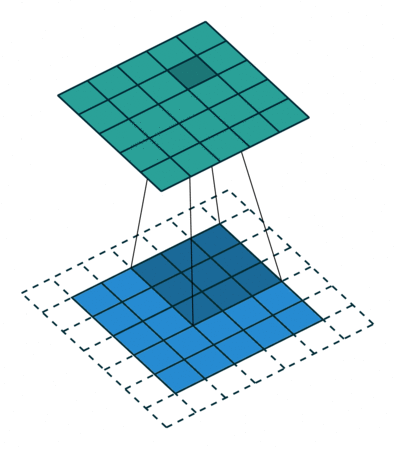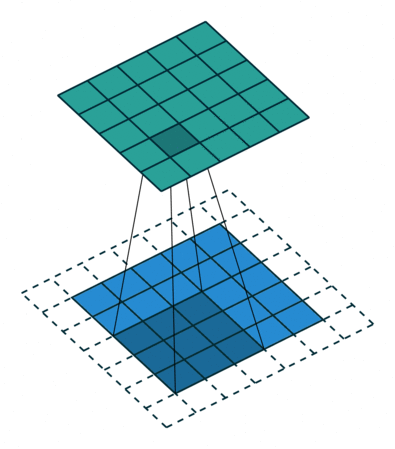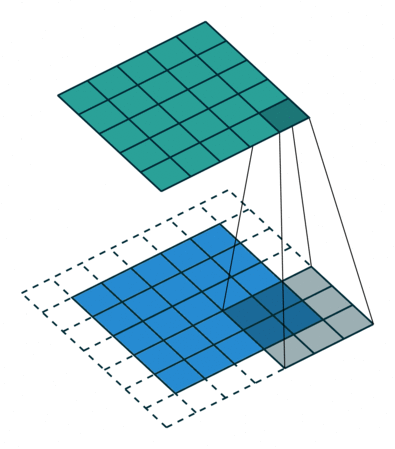
이미지 위에서 stride 값 만큼 filter(kernel)을 이동시키면서 겹쳐지는 부분의 각 원소의 값을 곱해서 모두 더한 값을 출력으로 하는 연산

즉, input에 filter로 Convolution 연산을 진행하면, 우측과 같이 output이 나온다는 것인데,

filter가 input의 왼쪽 상단에 위치한다고 했을 때, 계산 과정은 위와 같다는 것을 확인할 수 있을 것이다.
그래서 이를 filter를 이동시키며 연산을 하면 분홍색과 같은 output이 총 9개가 나오게 되며 3x3의 output이 출력된다.
Stride and Padding
Stride : filter를 한번에 얼마나 이동시킬 것인가
Padding : zero-padding
위의 경우에서는 Stride가 1이었다.
padding은 이미지 상하좌우에 padding의 값에 따라 0이 들어가있는 패드가 둘러지게 된다.
위의 경우는 padding이 zero-padding이었고,
아래의 경우는 padding 값이 1이다.

padding을 통해 외곽의 픽셀 데이터에 대한 활용도를 높이거나 conv연산의 특성상 input이미지 size가 줄어드는 것을 방지할 수 있다.
Pytorch nn.Conv2d
Pytorch에서 nn.Conv2d와 필터를 어떻게 선언해주는지 살펴보겠다.
먼저 Pytorch_nn.Conv2d Document에서 파라미터를 확인해보자. Pytorch 버전은 1.9.0 이다.
먼저 Conv2d는 여러 입력 평면으로 구성된 입력신호에 2D Convolution을 적용하는 과정을 위한 클래스라 할 수 있다.(직역)
Convolution Layer를 선언해주기 위한 과정이라 생각하면 좋을 것 같다.
매개변수는 다음과 같다.
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1,
bias=True, padding_mode='zeros', device=None, dtype=None)
in_channels : Number of channels in the input image
input 이미지의 채널의 수
out_channels : Number of channels produced by the convolution
output 이미지의 채널의 수
단(one) 채널이라면 input 채널과 동일하다.
kernel_size : Size of the convolving kernel
filter의 사이즈
3 by 3이면 3으로 작성하면 되고, 아닐 경우 3 by 5 라면 (3,5)와 같은 형식으로 작성한다.
stride : Stride of the convolution. Default: 1
위에서 언급한 것처럼 몇 칸씩 진행할지에 관한 매개변수
padding : Padding added to all four sides of the input. Default: 0
padding_mode : 'zeros', 'reflect', 'replicate' or 'circular'. Default: 'zeros'
dilation은 atrous 알고리즘으로도 불리고 필터(커널) 사이의 간격을 의미. (It is harder to describe)
group은 입력 채널과 출력 채널 사이의 관계를 나타내고 옵션은 다음과 같다.
group=1이면 모든 입력은 모든 출력과 convolution 연산이 됩니다. 일반적으로 알려진 convolution 연산을 한다.
groups=2이면 입력을 2그룹으로 나누어서 각각 convolution 연산을 하고 그 결과를 concatenation을 한다.
groups=in_channels이면 각각의 인풋 채널이 각각의 아웃풋 채널에 대응되어 convolution 연산을 하게 된다. 그 사이즈는 out_channels // in_channels가 된다.
입력의 형태, 출력의 크기
Convolution의 입력 타입(type)은 Torch.tensor이며
형태(Shape)는 다음과 같다.

이로 인한, 출력의 사이즈는 다음 수식을 통해 구할 수 있다.

nn.Conv2d Code
위의 사항들을 잘 고려하여 실제 코드를 어떻게 다뤄보는지 알아보자
import torch
import torch.nn as nn
conv = nn.Conv2d(1,1,11,stride = 4, padding = 0)
print (conv)
#result
Conv2d(1, 1, kernel_size=(11, 11), stride=(4, 4))
먼저, nn.Conv2d를 이용해 conv값을 정해준다.
inputs = torch.Tensor(1, 1, 227, 227)
inputs.shape
#result
torch.Size([1, 1, 227, 227])
그리고, input의 타입을 torch.Tensor 로 설정하고 위에서 다룬 input의 Shape에 따라 inputs를 설정해준다.
out = conv(inputs)
out.shape
#result
torch.Size([1, 1, 55, 55])
이제, 설정해놓은 input을 convolution 연산을 하게 되면 다음과 같은 Output의 형태가 정상적으로 출력됨을 확인할 수 있다.

Neuron과 Convolution
그렇다면 Neuron net과 Convolution이 어떠한 관계가 있고 실제로 어떻게 연산을 수행하는지 알아보자.

먼저, 위처럼 Convolution filter가 perceptron의 weight값으로 들어가고
input값이 stride 진행에 따라 filter 위치에 해당하는 값으로 각각 이동한다. (초반부에 설명한 것과 같은 것을 어떻게 연산하는지를 살피는 것이다.)


어떻게 매칭이 되고 있는건지 쉽게 확인할 수 있을 것이다.
그래서 계산한 결과가 8이지만 우리가 nn.Conv2d에서 bias에 관한 사항도 $ True $로 다뤄주었기에
실제 출력값은 $ 8 + bias $ 이다.
Pooling
이 연산은 이미지의 사이즈를 줄이기 위해 사용할 수도 있으며, 이 외에 fully connected 연산을 대체하기 위해 Average Pooling을 사용하는 경우도 있다.
Max Pooling

max pooling은 우리가 설정한 범위내에서 가장 큰 $i$를 출력해내는 방법이다.
예를 들어, size를 2로 잡았을때 2 by 2로 잡히고, 이 범위내에서 가장 큰 값($i$)를 출력하게 된다.
Average Pooling
Max가 가장 큰 값을 도출해낸것과 같이 Average도 말 그대로 설정해준 범위내에서의 평균을 계산해 출력을 하게 된다.
MAXPOOL2D(nn.MaxPool2d)
Pytorch_Pooling document에서 마찬가지로 클래스를 사용하기 위한 설명이 나와있다.
매개변수는 다음과 같다.
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1,
return_indices=False, ceil_mode=False)
kernel_size만 잘 설정해주면 된다. 나머지는 default.
CNN implementation
실제로 만들어보자.

다음과 같은 상황을 살펴보고 코드로 구현해보자.
Channel
우리가 x by x by 1인 input이미지를 사용하게 된다면 필터 또한 2d의 필터일 것이다.
이 때, 학습을 하다보면 Layer마다 channel의 개수를 늘려주는데 이것이 무엇을 의미하는 것일까?
위에서 설명한 것처럼,
필터는 weight를 담고 있다고 보면 되는데 이를 다른 weight를 가진 필터의 개수(채널)을 늘려가면
Activation map 또한 같은 개수로 늘어나게 된다.
1개의 input channel을 필터를 통해 Convolution 연산, pooling layer에서 연산을 통해 output을 도출해내는 상황이다.
코드를 살펴보자.
import torch
import torch.nn as nn
inputs = torch.Tensor(1, 1, 28, 28)
#input channel은 하나 #output channel은 5개 #filter size = 5
conv1 = nn.Conv2d(1, 5, 5)
filter size가 5이고, output 채널이 5개이기 때문에
5 by 5인 filter가 5개
pool = nn.MaxPool2d(2)
2 by 2 Max Pooling Vector size 설정
out = conv1(inputs)
Convoulution 연산
out2 = pool(out)
Pooling 연산
#userWarning C:\Users\LeeJaeWon\anaconda3\envs\DeepLearningStudy\lib\site-packages\torch\nn\functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at ..\c10/core/TensorImpl.h:1156.) return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)
위 오류의 의미(예상) : 해석해보면 본 클래스와 명명된 텐서가 실험적인 기능이며 변경될 수 있어서, 안정한 상태로 배포될 때까지 중요한 용도로 사용하지 말라는 의미인 것 같다.
out.size()
#result torch.Size([1, 5, 24, 24])
out2.size()
#result torch.Size([1, 5, 12, 12])
output의 사이즈가 계산되있음을 확인할 수 있다.
📣
본 포스팅의 학습 환경 : Anaconda, CPU, Pytorch, Jupyter Notebook
포스팅에서 오류나 궁금한 점은 Comments를 작성해주시면, 많은 도움이 됩니다.💡
Leave a comment